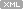
1. NULL != 공집합
!= SPACE
= NULL -- 결과: NULL
산술연산 -- 결과: NULL
비교연산 -- 결과: NULL
논리연산: 진리표 확인

SQL> select empno, sal, comm, comm from emp;
SQL> select empno, sal, comm, comm+100 from emp;
SQL> select empno, sal, comm, nvl(comm, 0)+100 from emp;
SQL> select empno, sal, comm, sal*12+comm from emp;
SQL> select empno, sal, comm, sal*12+nvl(comm, 0) from emp;
SQL> select sal*12+nvl(comm, 0) Ann_Sal,
sal*12+nvl(comm, 0) as Ann_Sal,
sal*12+nvl(comm, 0) "\Ann Sal"
from emp;
SQL> select * from emp where comm = null; -- 엉터리
SQL> select * from emp where comm is null; -- 제대로
SQL> select * from emp where deptno = 30 and comm = null; -- 엉터리
SQL> select * from emp where deptno = 30 or comm = null; -- 엉터리
SQL> select * from emp where deptno = 30 and comm is null; -- 제대로
SQL> select * from emp where deptno = 30 or comm is null; -- 제대로
2. IS NULL (IS NOT NULL)
SQL> select * from emp where comm = null; -- 엉터리
SQL> select * from emp where comm is null; -- 제대로
SQL> select * from emp where not(comm is null);
'개발 및 관리 > Oracle 9i, 10g, 11g, 12c, 19c' 카테고리의 다른 글
| 오라클 함수, SQL Functions (0) | 2012.11.08 |
|---|---|
| Access Predicate와 Filter Predicate - 오라클 성능 고도화 원리와 해법2 p.168~p.170 (0) | 2012.11.08 |
| (Oracle Database Server) 중앙정보처리학원 - 2012년 11월 06일 화요일 2/2 (0) | 2012.11.06 |
| (Oracle Database Server) 중앙정보처리학원 - 2012년 11월 06일 화요일 1/2 (0) | 2012.11.06 |
| 병렬 처리 활용(고급 SQL 튜닝) - SQL전문가 가이드 p.727~p.728 (0) | 2012.10.26 |





{kind=link}