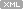1. HASH PARTITION TABLE
1)오라클 서버가 가장 최적으로 분할해 주기 때문에 개발자가 고민할 필요가 없다.
2)오라클 서버가 지정된 데이터 파일에 적절히 나누어서 저장해 준다.
3)데이터의 분할분포를 오라클 서버의 해시 알고리즘에 의해 처리하기 때문에 범위분할 방법보다 훨씬 분포도가 좋을 수 있으며,
일반적으로 2,4,6,8,16,32 단위로 분할한다.
CREATE TABLESPACE TBS1 DATAFILE 'C:\DISK1\TBS1.DBF' SIZE 1M;
CREATE TABLESPACE TBS2 DATAFILE 'C:\DISK1\TBS2.DBF' SIZE 1M;
CREATE TABLESPACE TBS3 DATAFILE 'C:\DISK1\TBS3.DBF' SIZE 1M;
CREATE TABLE JEON1
(ID DATE,
NAME CHAR(2))
PARTITION BY HASH (ID) PARTITION 3 STORE IN (TBS1, TBS2, TBS3);
또는
CREATE TABLE JEON1
(ID DATE, NAME CHAR(2))
PARTITION BY HASH (ID)
(PARTITION P1 TABLESPACE TBS1,
PARTITION P2 TABLESPACE TBS2,
PARTITION P3 TABLESPACE TBS3);
2. LIST PARTITION TABLE
CREATE TABLESPACE DATA01 DATAFILE 'C:\DISK1\DATA01.DBF' SIZE 1M;
CREATE TABLESPACE DATA02 DATAFILE 'C:\DISK1\DATA02.DBF' SIZE 1M;
CREATE TABLESPACE DATA03 DATAFILE 'C:\DISK1\DATA03.DBF' SIZE 1M;
CREATE TABLESPACE DATA04 DATAFILE 'C:\DISK1\DATA04.DBF' SIZE 1M;
CREATE TABLE LOCATIONS
(LOCATION_ID CHAR(2),
STREET_ADDRESS VARCHAR2(30),
POSTAL_CODE VARCHAR2(10),
CITY VARCHAR2(30),
STATE_PROVIENCE CHAR(2),
COUNTRY_ID CHAR(5))
PARTITION BY LIST (STATE_PROVIENCE)
(PARTITION REGION_EAST VALUES ('MA', 'NY', 'CT', 'NH', 'MD', 'VA', 'PA', 'NJ')
STORAGE (INITIAL 20K NEXT 40K PCTINCREASE 50) TABLESPACE DATA01,
PARTITION REGION_WEST VALUES ('CA', 'AZ', 'NM', 'OR', 'WA', 'UT', 'NV', 'CO')
STORAGE (INITIAL 20K NEXT 40K PCTINCREASE 50) TABLESPACE DATA02,
PARTITION REGION_SOUTH VALUES ('TX', 'KY', 'TN', 'LA', 'MS', 'AR', 'AL', 'GA') STORAGE (INITIAL 20K NEXT 40K
PCTINCREASE 50) TABLESPACE DATA03,
PARTITION REGION_CENTRAL VALUES '(OH', 'ND', 'SD', 'MO', 'IL', 'MI', NULL, 'IA')
STORAGE (INITIAL 20K NEXT 40K PCTINCREASE 50) TABLESPACE DATA04);
LIST PARTITION TABLE의 주요 특징
1)설정시 주의해야 할 내용은 분할되는 기준 값이 각 분할에서 중복적으로 정의되지 않아야 한다.
2)각각의 구별되는 컬럼의 값으로 데이터를 부할한다.
3)분류(sort)되지 않은, 전혀 관계(Relationship)가 없는 데이터에 대해 리스트 분할 방법을 적용할 수 있다.
4)분할(Partition) 사이에는 어떠한 관계(Relationship)도 존재하지 않는다.
5)데이터의 분할 및 성능에 향상 효과를 기대할 수 있다.