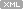

확인 결과 v$recovery_file_dest의 사이즈가 100G에 도달해서 DB가 down되는 문제였습니다.
1. DB 복구
C:\> sqlplus sys/test as sysdba
SQL> recover database until cancel;
SQL> alter database open resetlogs;
2. 파일 삭제(D드라이브의 backup 폴더로 이동)

3. RMAN으로 CROSSCHECK와 DELETE EXPIRED 수행
C:\> sqlplus sys/test as sysdba
SQL> alter database begin backup;
SQL> alter database end backup;
SQL> alter system checkpoint;
SQL> alter system switch logfiile;
SQL> host
C:\> rman target sys/test
RMAN> crosscheck archivelog all;
RMAN> delete expired archivelog all; [yes]
4. 사이즈 확인
SQL> select name, floor(space_limit/1024/1024) "Size MB", ceil(space_used/1024/1024) "Used MB" from v$recovery_file_dest order by name;

-------------------------------------------------------------------------------------------------
recovery dest 는
최종 온라인 백업 된 이후의 로그들을 지울수 있습니다.
db에 접속하셔서
alter database begin backup
alter database end backup 찍으시고,
alter system checkpoint 찍으시고,
이후에, alter system switch logfiile 하신후에
rman target /nolog 로 접속 하시고,
crosscheck archive og all;
delete expired archivelog all; [yes]
-------------------------------------------------------------------------------------------------
http://majesty76.tistory.com/54
 ORA-16038, ORA-19809, ORA-00312.doc
ORA-16038, ORA-19809, ORA-00312.doc
'개발 및 관리 > Oracle 9i, 10g, 11g, 12c, 19c' 카테고리의 다른 글
| NVL(oracle)/ISNULL(mssql) 함수의 특성, SQL전문가 가이드 p.245 (0) | 2012.03.28 |
|---|---|
| 단일행 CASE 표현의 종류, SQL전문가 가이드 p. 242 (0) | 2012.03.28 |
| AUTOTRACE(이펙티브 오라클에서 발취, 정보문화사, TOMAS KTYE저) (0) | 2012.02.13 |
| Static vs. Dynamic SQL (0) | 2012.02.13 |
| ORA-27100 Shared Memory Realm Already Exist (0) | 2011.11.16 |











